Kierownik utrzymania | IT
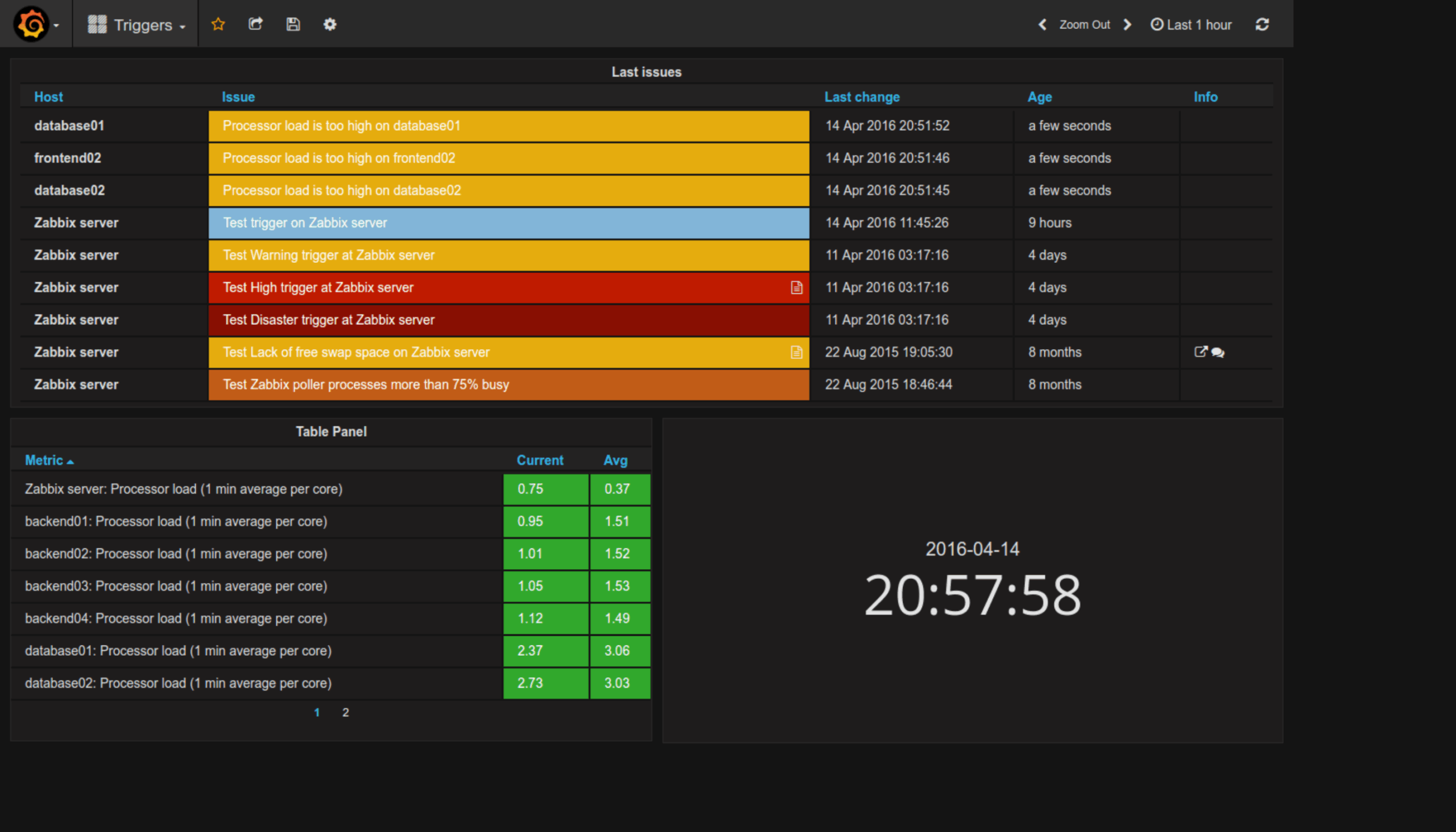
„W złożonej i rozproszonej architekturze brakowało jednego, centralnego punktu monitorowania, który pozwalałby weryfikować dostępność urządzeń, sprawność transmisji danych i zgodność z wymaganiami SLA.”
„W złożonej i rozproszonej architekturze brakowało jednego, centralnego punktu monitorowania, który pozwalałby weryfikować dostępność urządzeń, sprawność transmisji danych i zgodność z wymaganiami SLA.”
„Nie możemy pozwolić sobie na domysły. Potrzebujemy jednoznacznych informacji, czy dana usługa działa, zanim zarząd zapyta, dlaczego nie ma raportu.”
Co jest krytyczne, a co ostrzeżeniem? Które alerty wymagają natychmiastowej reakcji, a które można obserwować? Czy problem dotyczy jednego hosta czy wielu oraz czy eskaluje w czasie?
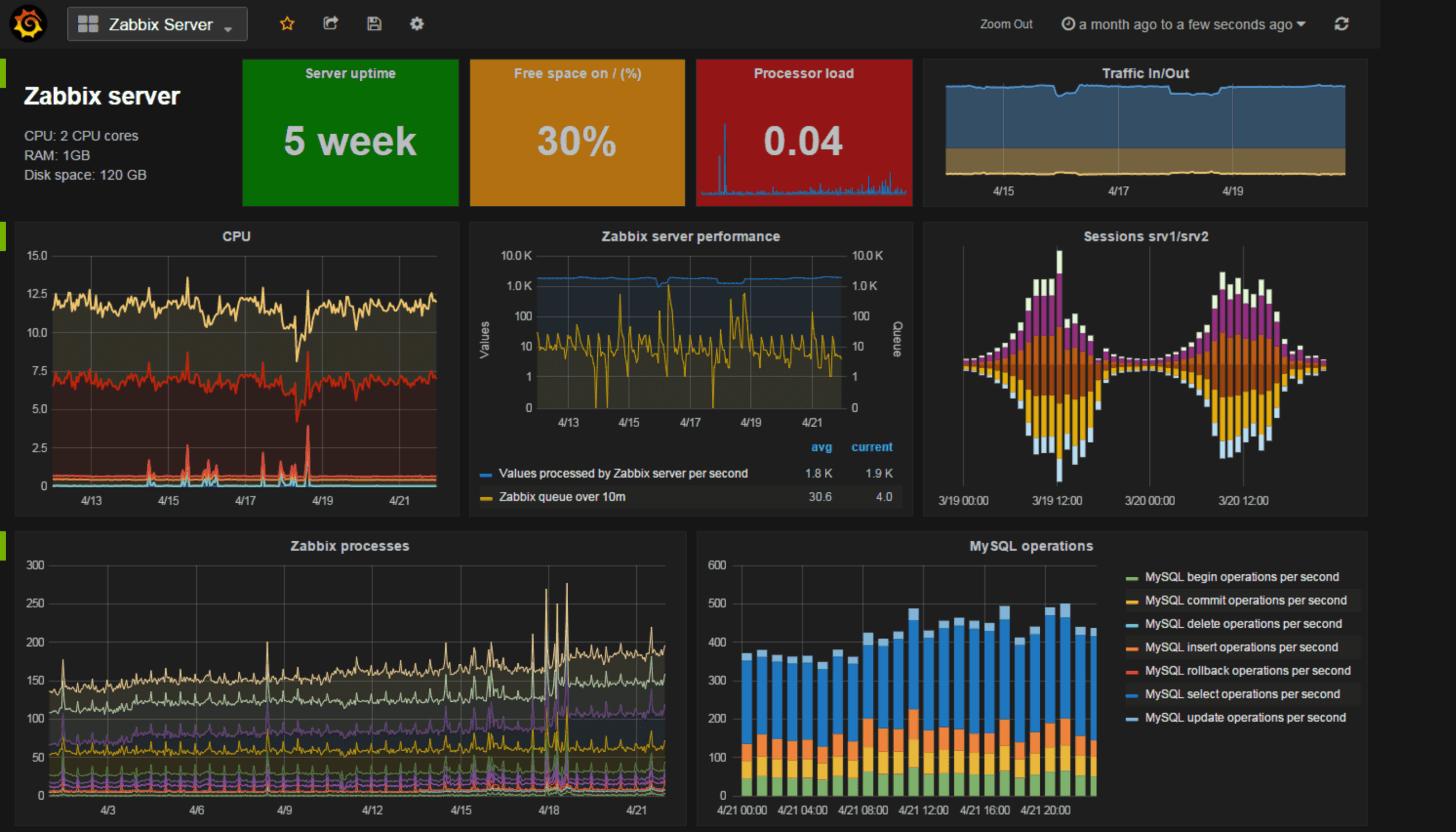
Czy Zabbix działa stabilnie? Czy kolejki, procesy lub baza danych są wąskim gardłem? Czy obciążenie wpływa na jakość danych i SLA? Czy to incydent czy trend wymagający skalowania?
„Zespół reagował na alerty, ale brakowało wspólnego widoku sytuacji.”
„Mieliśmy dane techniczne, ale brakowało syntetycznego obrazu dla zarządu.”
„Sprzedaż spadała, ale trudno było szybko powiązać to z problemem technicznym.”
„Problemy wychodziły dopiero wtedy, gdy opóźnienia były już widoczne w realizacji.”
„Systemy działały, ale brakowało jasnej informacji, co dokładnie jest przyczyną przestojów.”
„Przed wdrożeniem dashboardów Grafany dane operacyjne były rozproszone. Brakowało jednego punktu odniesienia.”
{kind=link}